Abstract
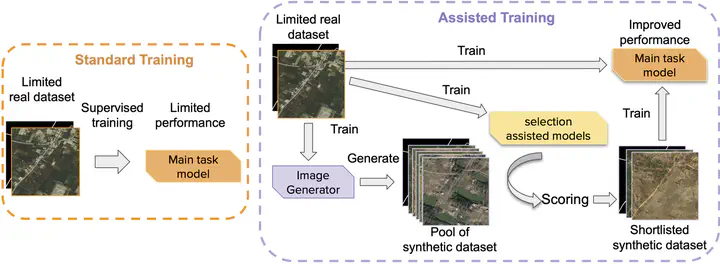
Geo-information extraction from satellite imagery has become crucial to carry out large-scale ground surveys in a short amount of time. With the increasing number of commercial satellites launched into orbit in recent years, high-resolution RGB color remote sensing imagery has attracted a lot of attention. However, because of the high cost of image acquisition and even more complicated annotation procedures, there are limited high-resolution satellite datasets available. Compared to close-range imagery datasets, existing satellite datasets have a much lower number of images and cover only a few scenarios (cities, background environments, etc.). They may not be sufficient for training robust learning models that fit all environmental conditions or be representative enough for training regional models that optimize for local scenarios. Instead of collecting and annotating more data, using synthetic images could be another solution to boost the performance of a model. This study proposes a GAN-assisted training scheme for road segmentation from high-resolution RGB color satellite images, which includes three critical components: a) synthetic training sample generation, b) synthetic training sample selection, and c) assisted training strategy. Apart from the GeoPalette and cSinGAN image generators introduced in our prior work, this paper in detail explains how to generate new training pairs using OpenStreetMap (OSM) and introduces a new set of evaluation metrics for selecting synthetic training pairs from a pool of generated samples. We conduct extensive quantitative and qualitative experiments to compare different image generators and training strategies. Our experiments on the downstream road segmentation task show that 1) our proposed metrics are more aligned with the trained model performance compared to commonly used GAN evaluation metrics such as the Fréchet inception distance (FID); and 2) by using synthetic data with the best training strategy, the model performance, mean Intersection over Union (mean IoU), is improved from 60.92% to 64.44%, when 1,000 real training pairs are available for learning, which reaches a similar level of performance as a model that is standard-trained with 4,000 real images (64.59%), i.e., enabling a 4-fold reduction in real dataset size.
Hu Wenmiao
Ph.D. candidate & Ph.D. Researcher
Ph.D. National University of Singapore (2024), Ph.D. researcher at Grab, Grab NUS AI Lab.